Legal research has always been about finding the right precedent — the decision that aligns with your facts, your jurisdiction, and your client's needs. But in a world of ever-growing case law, getting from every opinion ever written to the one you can rely on in court is harder than ever. Precedent AI was built to change that.
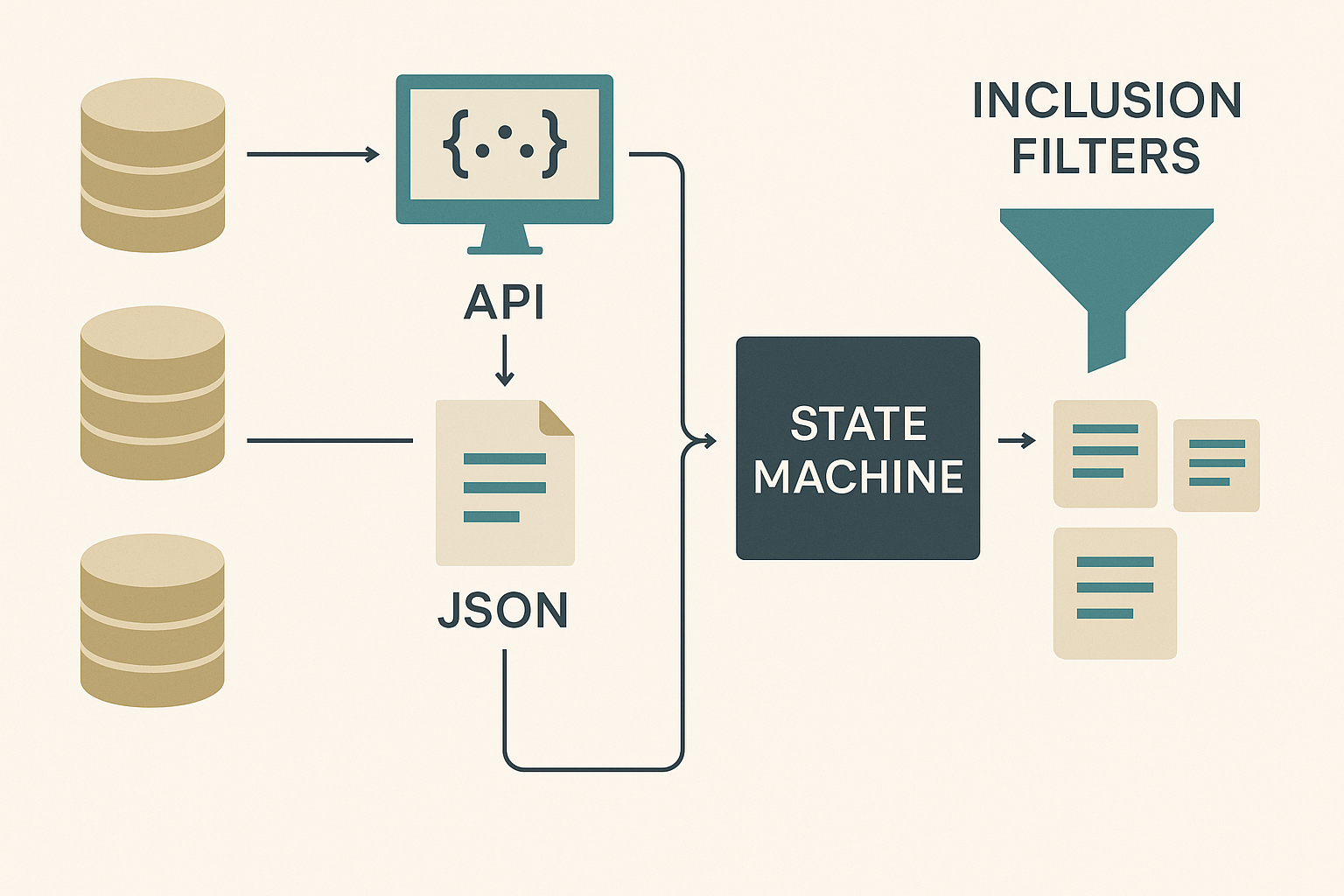
At the heart of our platform is a data ingestion process designed specifically for legal research. Think of it as a pipeline that takes in raw court opinions and transforms them into a curated, explainable, and AI-ready legal corpus. It all starts with something we call a seed pack — a focused blueprint for a particular area of law. For example, North Carolina Restrictive Covenants in Employment might be one seed pack, defining which courts matter, what time range to consider, and which landmark cases to start from.
From these seeds, the system grows outward. We gather every case that cites a seed (forward citations) and every case the seed cites (backward citations). In some situations, we add targeted keyword searches to capture edge cases. This expansion follows the natural network of legal reasoning, pulling in the decisions most likely to be relevant while avoiding the flood of unrelated results that pure keyword search can create.
Once we have this expanded set, we apply inclusion filters to keep only the cases that match the pack's jurisdiction, date range, and topic. Then we layer in quality controls: deduplicating, normalizing citations, classifying for topical focus, and ranking cases by importance, recency, and connectedness to other key decisions. The end result is a balanced, high-quality dataset for that specific area of law.
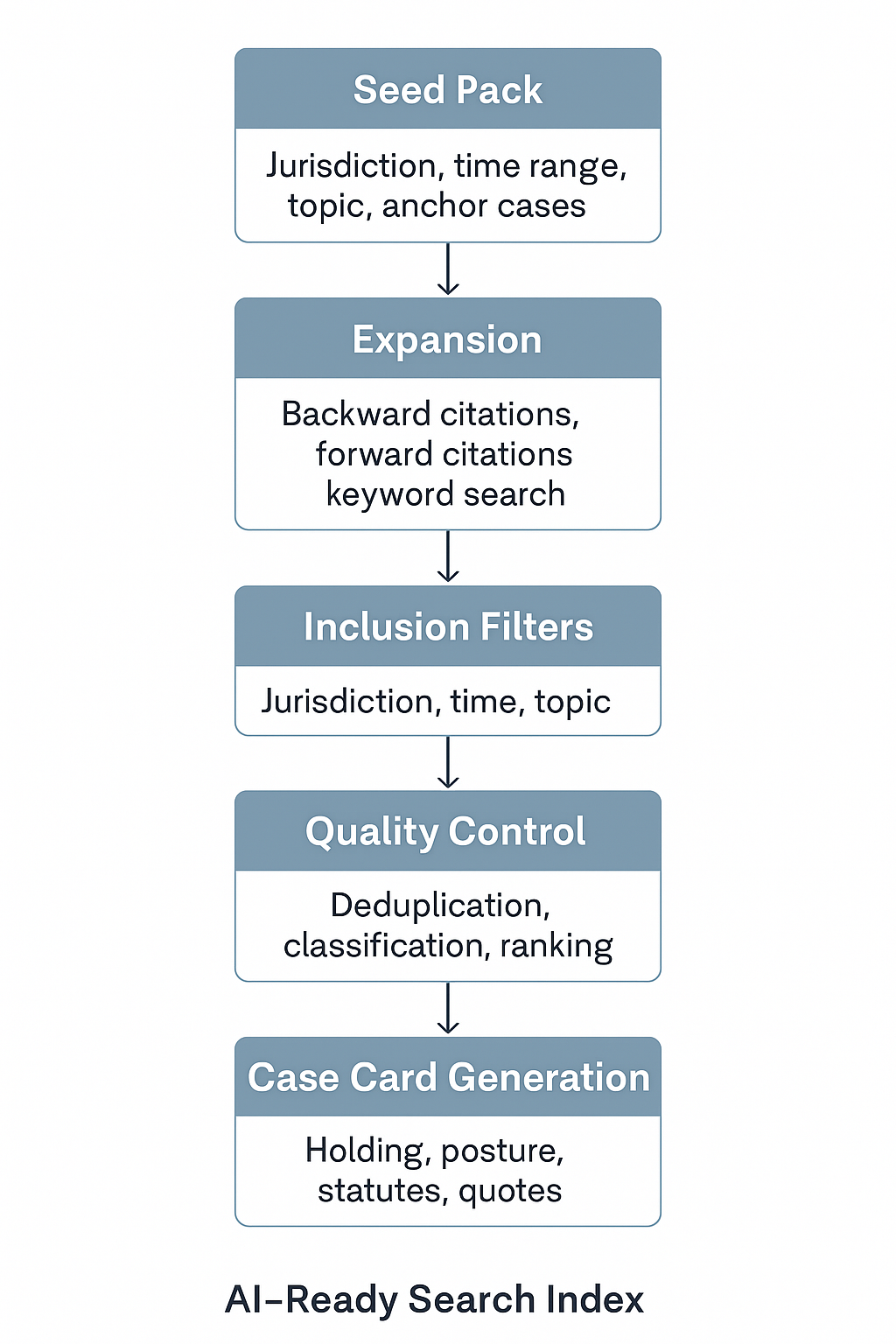
Precedent AI's data ingestion pipeline transforms raw court opinions into AI-ready insights through systematic filtering and enrichment.
The final step is enrichment. For every retained case, Precedent AI generates a structured "case card" that captures the holding, procedural posture, statutes cited, and the key quotes — with exact pincites — that make the case useful. These cards, along with the full opinion text, are added to our search index, which supports both traditional keyword search and modern semantic retrieval. This means our AI can answer your question and show you exactly where the law says what it says.
And here's the best part — this process works for any topic, in any jurisdiction, and from any data source. Today we're using public APIs like CourtListener. Tomorrow we can integrate licensed legal databases, state court portals, or even firm-specific document repositories — all without changing how the rest of the pipeline works.
For lawyers, this means answers that are both faster and more trustworthy. For legal tech teams, it's a repeatable, configurable ingestion process that can grow from one narrowly focused seed pack to a multi-jurisdiction, multi-topic legal research platform.
The law is constantly evolving. With Precedent AI's ingestion pipeline, so is your research.